构建高效数据处理服务 连接业务服务器与大数据服务器的关键纽带
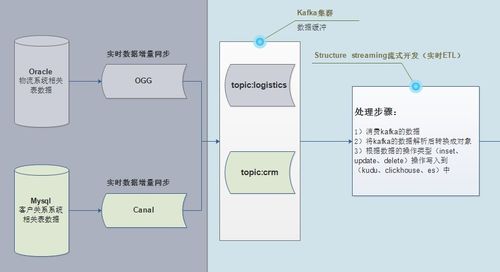
在现代化的大数据物流项目中,数据处理服务扮演着至关重要的角色,它不仅是业务服务器与大数据服务器之间的桥梁,更是驱动整个物流系统智能化、高效化的核心引擎。本文将深入探讨数据处理服务在两者间的定位、核心功能以及最佳实践。
一、数据处理服务的核心定位
数据处理服务并非简单的数据搬运工,而是一个智能化的数据加工与调度中心。它位于前端业务服务器与后端大数据服务器之间,承担着以下关键使命:
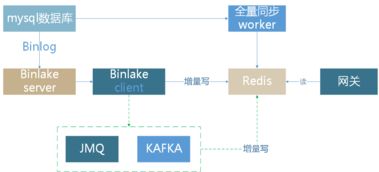
- 实时数据接入与缓冲:从业务服务器(如订单系统、仓储管理系统、运输管理系统)实时接收高并发、多格式的业务数据(如订单信息、车辆GPS位置、库存变动),进行初步清洗与标准化,并缓冲至消息队列(如Kafka),以削峰填谷,保护后端大数据集群。
- 数据预处理与质量管控:对原始数据进行过滤、去重、格式转换、异常值检测与修复,确保流入大数据服务器的数据质量。例如,校验运单号的合法性、补全缺失的邮政编码、统一时间戳格式。
- 任务调度与流程编排:作为数据管道的“指挥中枢”,它协调ETL(抽取、转换、加载)任务的执行顺序,例如,在每日凌晨定时触发数据从业务数据库向数据仓库的同步,并在完成后自动启动当日的货量预测分析作业。
- 服务解耦与接口统一:将业务服务器从复杂的数据计算任务中解放出来,使其专注于业务流程;为上游业务方提供统一、简洁的数据查询与写入API,隐藏后端大数据集群(如Hadoop、Spark、Flink集群)的技术复杂性。
二、关键功能模块设计
一个稳健的数据处理服务通常包含以下模块:
- 实时流处理引擎:采用Apache Flink或Spark Streaming,对物流轨迹、设备传感器数据进行实时计算,实现运输时效监控、异常路径预警。
- 批量数据处理管道:利用Apache Airflow或DolphinScheduler进行任务调度,定时执行大批量数据的ETL作业,如历史订单数据的归档、成本报表的生成。
- 数据质量管理中心:内置数据质量规则库,对数据进行校验、监控与报告,确保分析结果的可靠性。
- 元数据管理与数据目录:记录数据资产的来源、格式、血缘关系与变更历史,提升数据的可发现性与可管理性。
- 监控与告警系统:实时监控数据管道的健康状态、处理延迟与资源消耗,出现异常时及时通知运维团队。
三、实现中的最佳实践
- 架构选型:采用微服务架构,将不同的数据处理功能(如实时计算、批量同步、质量检查)拆分为独立服务,便于开发、部署与扩展。
- 容错与高可用:数据处理服务本身应设计为无状态或状态可恢复,利用集群部署和负载均衡避免单点故障。关键数据通道需具备重试机制与死信队列处理。
- 性能优化:针对物流数据特点进行优化,例如,对时空数据(位置、时间)采用专用序列化格式;在数据进入大数据服务器前,进行合理的分区与预聚合,提升后续分析效率。
- 安全与合规:对敏感数据(如客户信息)在传输与处理过程中进行脱敏或加密,并建立严格的访问权限控制,满足数据安全法规要求。
四、带来的核心价值
通过部署专业的数据处理服务,大数据物流项目能够:
- 提升运营效率:实现从订单到配送的全链路数据实时可视与智能分析,助力动态路径规划、仓网优化。
- 增强决策智能:为管理层提供准确、及时的KPI仪表盘与预测模型(如需求预测、运力预测),支撑数据驱动决策。
- 保障系统稳定:通过缓冲与解耦,保护核心业务系统与昂贵的大数据集群免受流量冲击与相互干扰。
- 加速数据价值变现:标准化、高质量的数据湖/仓是高级分析(如机器学习优化)的基石,能更快孵化出智能调度、风险预警等创新应用。
数据处理服务是激活大数据物流项目潜力的“神经中枢”。它通过精巧的设计与高效的执行,将前端业务产生的数据“原油”,提炼成可供分析决策的“高价值燃料”,并安全、稳定地输送至大数据服务器,最终驱动整个物流网络向着更智能、更敏捷的方向持续进化。
如若转载,请注明出处:http://www.tfileoutdoors.com/product/12.html
更新时间:2026-06-19 11:15:20